.webp)

当前使用的是k8s,1.30版本,其他新的版本也是同此方法,可以官网看最新版本
K8S的1.30版本特性:
· kubelet 重启后稳健的 VolumeManager 重建(SIG Storage)
· 防止在卷还原过程中未经授权的卷模式转换(SIG Storage)
· Pod 调度可用性(SIG Scheduling)
· PodTopologySpread 中的最小域数(SIG Scheduling)
· k/k 中的 Go 工作区(SIG Architecture))
· 节点日志查询(Windows SIG Scheduling)
· CRD 验证棘轮(SIG API Machinery)
· 上下文日志记录(SIG Instrumentation)
· 使 Kubernetes 了解负载均衡行为(SIG Network)
一、k8s环境初始化
注意:未特殊说明所有主机均需配置
1.1、环境准备 服务器要求
建议最小硬件配置:2核cpu ,4G内存,40G硬盘
建议操作系统:centos 7.6及其以上,推荐centos 7.9 或者rock ,本质都是centos系统
软件环境(本教程采用版本)
操作系统:rocky 9.6
docker:26.1.6
cri-dockerd :0.3.1
k8s: v1.30.10
服务器规划
1.2、主机域名解析
为方便后续集群节点使用主机名进行调用,在hosts中配置主机名解析,企业中推荐使用内部DNS服务 器进行通信
cat >> /etc/hosts << EOF
192.168.56.7 master01
192.168.56.9 node01
192.168.56.10 node02
EOF
1.3、设置时区
timedatectl set-timezone Asia/Shanghai
1.4、禁用防火墙
#关闭防火墙
systemctl stop firewalld
#取消防火墙开机自启动
systemctl disable firewalld
1.5、关闭selinx
#临时关闭selinux
setenforce 0
#永久关闭selinux
sed -i s/SELINUX=.*/SELINUX=disabled/gI /etc/selinux/config
1.6、禁用swap分区,如果不设置kubelet无法启动
#关闭swap分区
swapoff -a
#防止开机启动
sed -i /swap/s/^/#/ /etc/fstab
1.7、修改linux内核参数
cat >> /etc/sysctl.d/k8s.conf << EOF
vm.swappiness=0
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
EOF
------------------------------分割线------------------------
modprobe br_netfilter
modprobe overlay
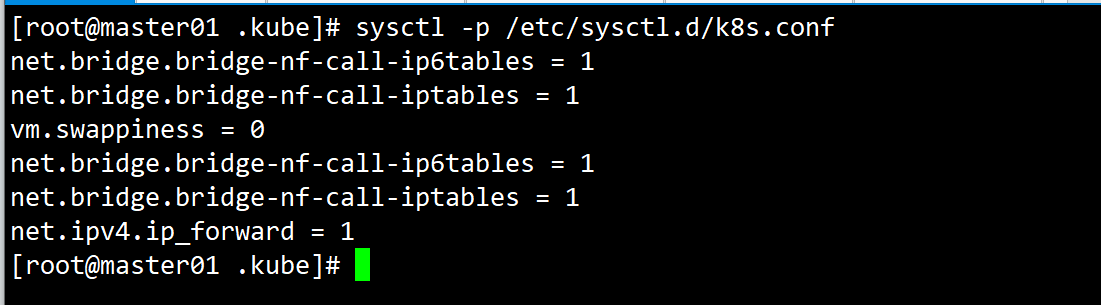
sysctl -p /etc/sysctl.d/k8s.conf
如图示结果:
二、docker离线安装部署
2.1、进入到docker软件包目录
cd docker-soft/
2.2、解压docker安装包
tar -zxvf docker-26.1.2.tgz
2.3、将docker文件复制到指定目录下
cp docker/* /usr/bin/
2.4、注册docker为系统服务
cat > /etc/systemd/system/docker.service <<'EOF'
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/bin/dockerd
ExecReload=/bin/kill -s HUP $MAINPID
LimitNOFILE=infinity
LimitNPROC=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF
2.5、给文件添加可执行权限
chmod +x /etc/systemd/system/docker.service
2.5、配置镜像下载加速
mkdir /etc/docker
cat > /etc/docker/daemon.json <<'EOF'
{
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://docker.registry.cyou",
"https://docker.1ms.run",
"https://docker-cf.registry.cyou",
"https://dockercf.jsdelivr.fyi",
"https://docker.jsdelivr.fyi",
"https://dockertest.jsdelivr.fyi",
"https://mirror.aliyuncs.com",
"https://dockerproxy.com",
"https://mirror.baidubce.com",
"https://docker.m.daocloud.io",
"https://docker.nju.edu.cn",
"https://docker.mirrors.sjtug.sjtu.edu.cn",
"https://docker.mirrors.ustc.edu.cn",
"https://mirror.iscas.ac.cn",
"https://docker.rainbond.cc"
],
"data-root": "/var/lib/docker",
"storage-driver": "overlay2",
"log-driver": "json-file",
"log-opts": {
"max-size": "100m",
"max-file": "3"
}
}
EOF
2.6、启动并设置开机自动
systemctl daemon-reload
systemctl enable docker.service
systemctl restart docker
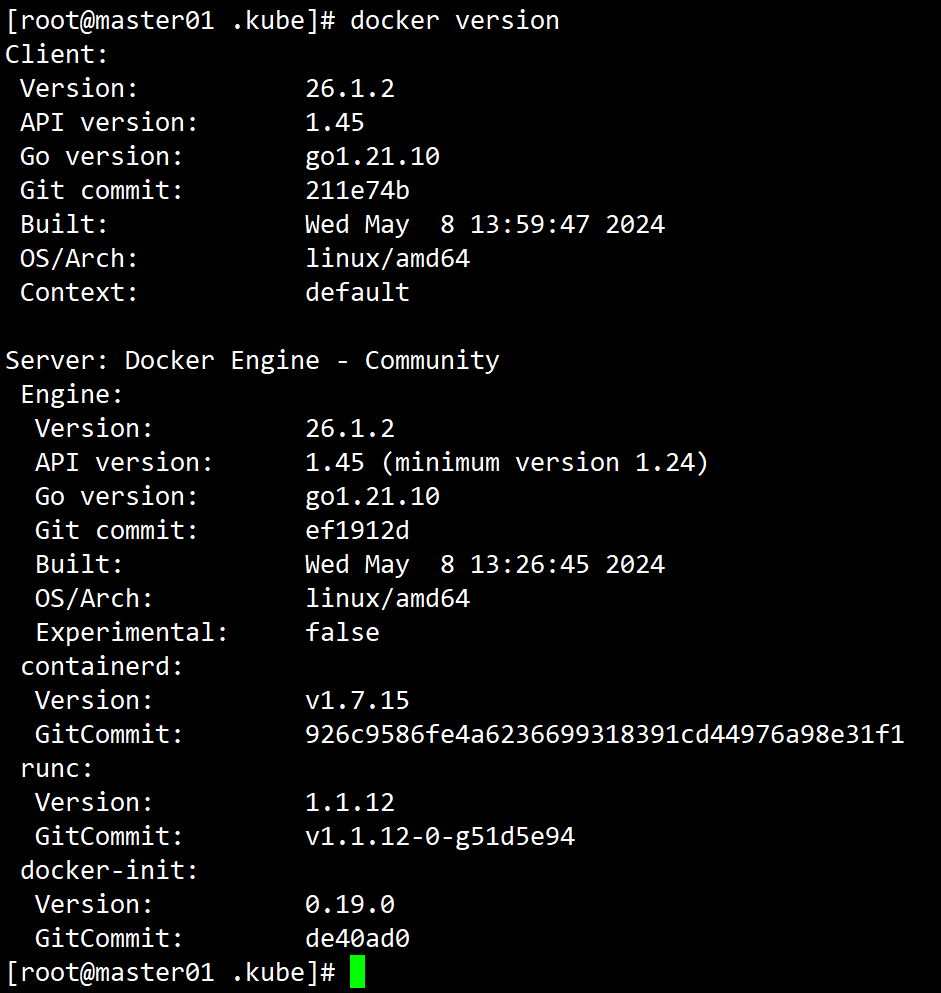
2.7、验证docker
三、docker-cri离线安装部署
Kubernetes v1.24移除docker-shim的够支持到CRI规范的桥梁支持,而Docker Engine默认又不
支持CRI标准,因此二者默认无法再直接集成。为此,Mirantis和Docker联合创建了cri-dockerd项
目,用于为Docker Engine提供一个能够让Docker作为Kubernetes容器引擎。
3.1、安装docker-cri
tar zxvf cri-dockerd-0.3.14.amd64.tgz
#将解压之后的docker文件移到bin目录下
cp cri-dockerd/cri-dockerd /usr/bin/
3.2、将docker-cri注册成系统启动服务
cat > /usr/lib/systemd/system/cri-docker.service <<'EOF'
[Unit]
Description=CRI Interface forDocker Application Container Engine
Documentation=https://docs.mirantis.com
After=network-online.targetfirewalld.service docker.service
Wants=network-online.target
Requires=cri-docker.socket
[Service]
Type=notify
ExecStart=/usr/bin/cri-dockerd --container-runtime-endpoint fd:// --network-plugin=cni --cni-bin-dir=/opt/cni/bin --cni-cache-dir=/var/lib/cni/cache --cni-conf-dir=/etc/cni/net.d --pod-infra-container-image=registry.aliyuncs.com/google_containers/pause:3.9
ExecReload=/bin/kill -s HUP$MAINPID
TimeoutSec=0
RestartSec=2
Restart=always
StartLimitBurst=3
StartLimitInterval=60s
LimitNOFILE=infinity
LimitNPROC=infinity
LimitCORE=infinity
TasksMax=infinity
Delegate=yes
KillMode=process
[Install]
WantedBy=multi-user.target
EOF
注册cri-docker.socket
cat > /usr/lib/systemd/system/cri-docker.socket <<'EOF'
[Unit]
Description=CRI Docker Socket forthe API
PartOf=cri-docker.service
[Socket]
ListenStream=%t/cri-dockerd.sock
SocketMode=0660
SocketUser=root
SocketGroup=root
[Install]
WantedBy=sockets.target
EOF
3.6、启动并设置开机自启
systemctl start cri-docker && systemctl enable cri-docker
3.7、验证cri是否启动
正常是处于running
systemctl status cri-docker
四、k8s安装部署
4.1、导入镜像和k8s软件包
cd k8s-images/
docker load -i k8s-v1.30.10-images.tar
4.2、安装kubeadm、kubelet和kubectl
cd k8s-soft-rpm/
yum localinstall ./*.rpm -y
4.3、配置kubelet和cri-docker
#.配置kubelet服务, 修改/etc/sysconfig/kubelet文件的KUBELET_KUBEADM_ARGS字段
echo KUBELET_KUBEADM_ARGS="--container-runtime-endpoint=/run/cri-dockerd.sock" > /etc/sysconfig/kubelet
4.4、启动kubelet
systemctl enable --now kubelet
4.5、初始化k8s集群
注意:只需要在master进行操作
apiserver-advertise-address 集群通告地址,此处修改为自己master节点IP
image-repository 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里指定阿里云镜像仓库地址
kubernetes-version K8s版本,与上面安装的一致
service-cidr 集群内部虚拟网络,Pod统一访问入口
pod-network-cidr Pod网络
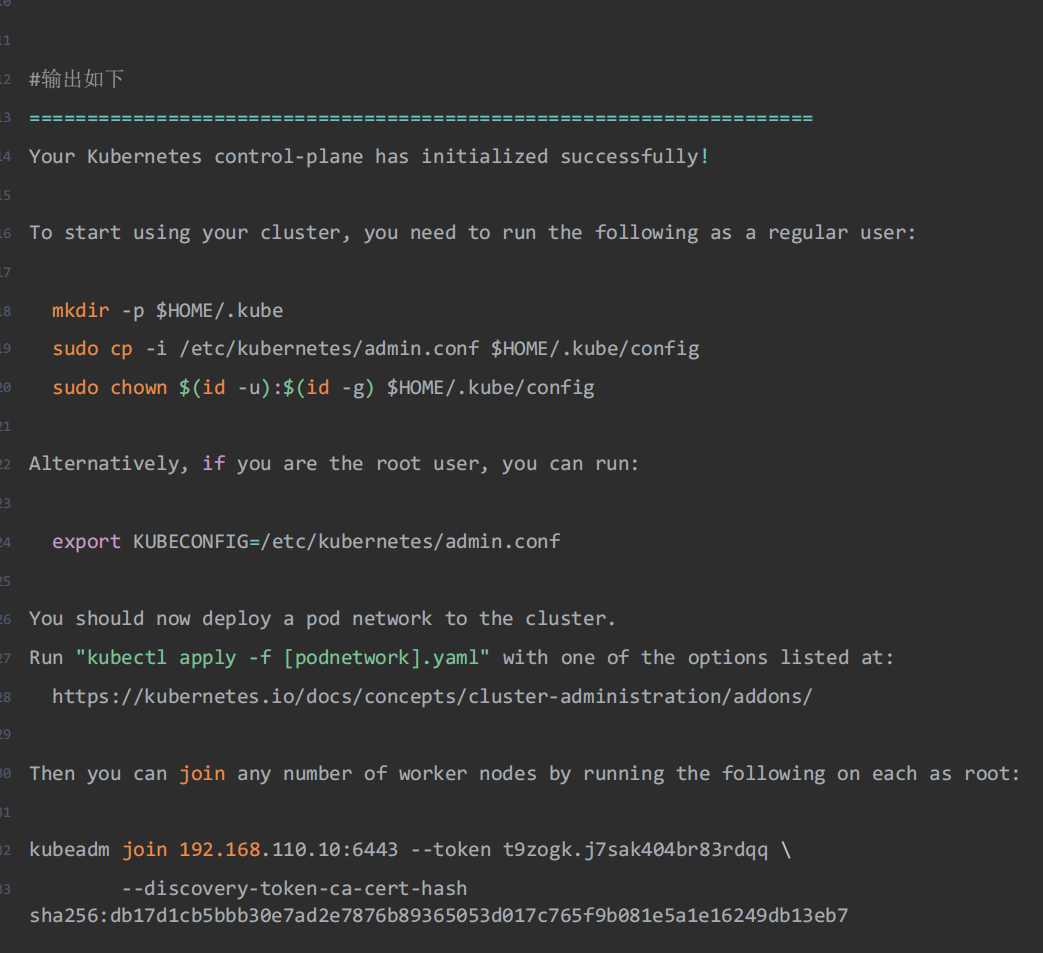
kubeadm init --apiserver-advertise-address=192.168.56.7 --image-repository registry.aliyuncs.com/google_containers --kubernetes-version v1.30.10 --service-cidr=10.96.0.0/12 --pod-network-cidr=10.244.0.0/16 --token-ttl=0 --upload-certs --cri-socket unix:///var/run/cri-dockerd.sock
初始化正常输出如下:
添加集群配置
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
4.6、初始化失败处理方案
如果初始化失败,则需要执行以下命令在重新进行初始化,如果初始化成功此步骤不用操作
kubeadm reset -f --cri-socket=unix:///var/run/cri-dockerd.sock
rm -rf ~/.kube
此时,使用kubectl get nodes,注意到所有节点的状态都是 “NotReady”,这是由于集群还缺少网络插件,集群的内部网络还没有正常运作。
五、网络插件离线部署
kubernetes支持多种网络插件,比如flannel、calico等,任选一种,推荐flannel
5.1、安装flannel
cd k8s-soft-rpm/
kubectl apply -f ./kube-flannel.yml
5.2、calico网络插件离线部署
calico官网地址:https://docs.tigera.io/calico/3.27/about
点击此处下载calico离线安装包
calico包单独发送
1. 将镜像导入到docker
docker load -i calico-master.tar
2. 安装Tigera-Calico管理和自定义资源定义
kubectl create -f tigera-operator.yaml
3. 通过创建必要的自定义资源来安装Calico
kubectl create -f custom-resources.yaml
5.3、验证master处于reday状态
六、node节点加入集群
6.1、执行加入命令
kubeadm join 192.168.56.7:6443 --token iuirah.g5xgliaj0xoexot3 \
--discovery-token-ca-cert-hash sha256:febac1a7e34272f5aa4a5aefa5aeb6ee7628a3b7f0283a41d919cd2cae945800 \
--cri-socket unix:///var/run/cri-dockerd.sock
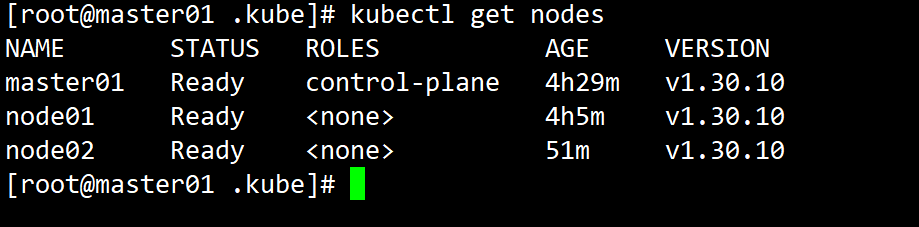
6.2、在master节点进行验证
七、 master重置集群
kubeadm reset -f --cri-socket=unix:///var/run/cri-dockerd.sock
rm -rf ~/.kube
八、常见问题
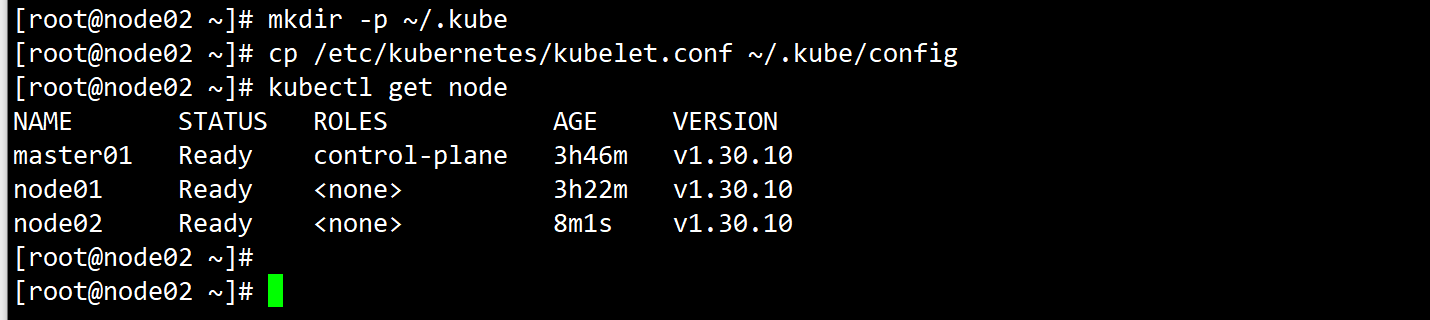
1、使用kubectl get nodes 出现报错提示连接localhost:8080失败的原因及解决方案
原因:kubectl get node命令需要通过 Kubernetes API Server 获取集群节点信息,系统报错“dial tcp [::1]:8080: connection refused”表明:kubectl未正确配置集群API Server地址,默认尝试连接本地(Node节点)的localhost:8080端口(Kubernetes早期默认API Server端口,但现代集群已使用6443端口且API Server仅运行在Master节点,Node节点无API Server进程),导致连接失败。

解决方法:
分两种情况,第一种是master节点报错
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
第二种是
(1)创建文件夹
mkdir -p $HOME/.kube
(2)把配置文件复制进刚刚新创建的文件夹里
cp /etc/kubernetes/kubelet.conf ~/.kube/config # 复制集群配置到默认路径
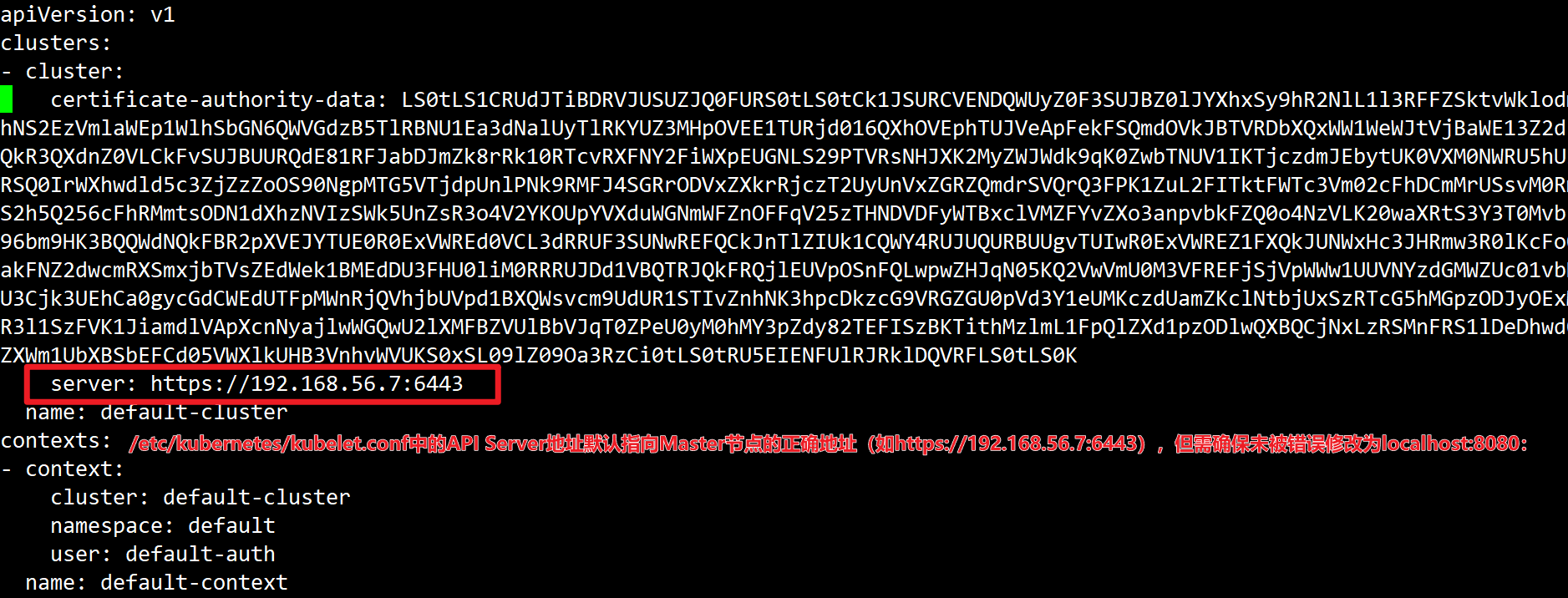
(3)/etc/kubernetes/kubelet.conf中的API Server地址默认指向Master节点的正确地址(如https://192.168.56.7:6443),但需确保未被错误修改为 localhost:8080:
打开~/.kube/config文件,查看是否配置为server: https://192.168.56.7:6443 # 正确:指向Master节点API Server的IP和6443端口
若server字段为http://localhost:8080,需要更改为https://192.168.56.7:6443
2、集群添加node节点,通过journalctl -n kubelet 发现报错了(sudo journalctl -u kubelet -f # -u指定服务,-f实时查看最新日志),出现提示缺文件,但是实际上已经是有文件了,启动systemct start kubelet 也报错,重置后重新授权就可以,参考第3点解决方法。
报错:unable to read existing bootstrap client config from /etc/kubernetes/kubelet.conf: invalid configuration: [unable to read client-cert /var/lib/kubelet/pki/kubelet-client-current.pem for default-auth due to open /var/lib/kubelet/pki/kubelet-client-current.pem: no such file or directory, unable to read client-key /var/lib/kubelet/pki/kubelet-client-current.pem for default-auth due to open /var/lib/kubelet/pki/kubelet-client-current.pem: no such file or directory]

这里提供新的解决方法:备份kubelet文件,然后重新生成相关的文件。
$ cd /etc/kubernetes/pki/
$ mv {apiserver.crt,apiserver-etcd-client.key,apiserver-kubelet-client.crt,front-proxy-ca.crt,front-proxy-client.crt,front-proxy-client.key,front-proxy-ca.key,apiserver-kubelet-client.key,apiserver.key,apiserver-etcd-client.crt} ~/
$ kubeadm init phase certs all
$ cd /etc/kubernetes/
$ mv {admin.conf,controller-manager.conf,kubelet.conf,scheduler.conf} ~/
$ kubeadm init phase kubeconfig all
$ reboot
$ cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
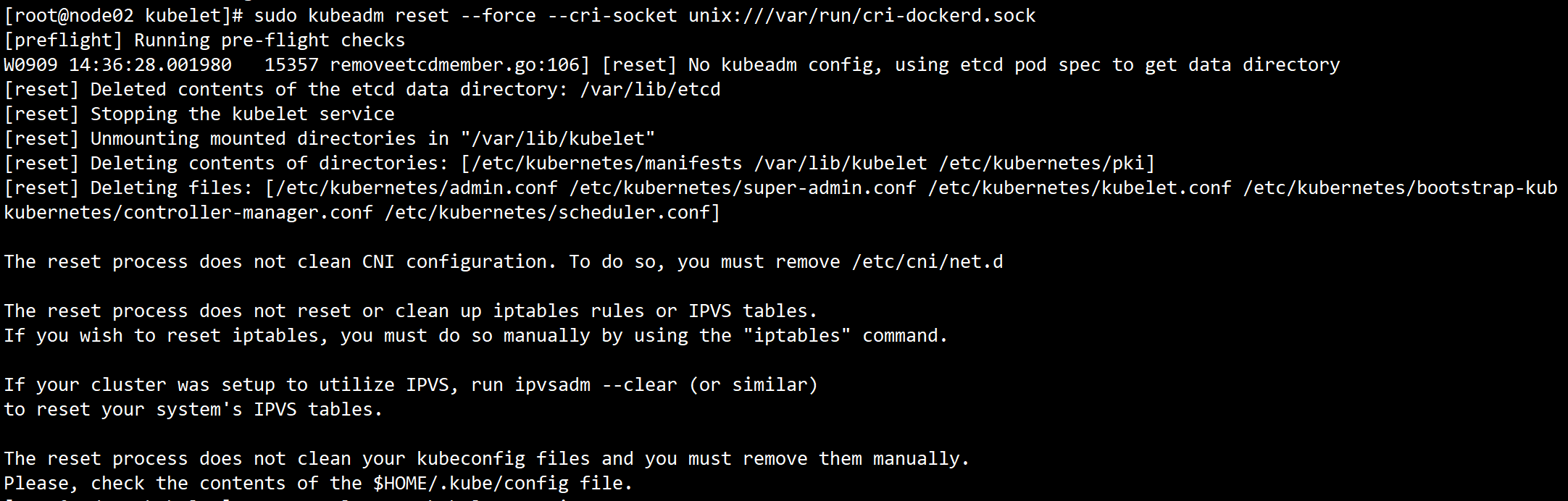
3、想重置某一个节点,sudo kubeadm reset --force # --force:强制清理后,报错提示:
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
node节点重置集群
这是因为系统存在多个sock,需要指定需要加上--cri-socket unix:///var/run/cri-dockerd.sock。
正确指令:
清理内容包括:
/etc/kubernetes/目录下的配置文件(如kubelet.conf bootstrap-kubelet.conf);
/var/lib/kubelet/ /.minikube/等数据目录;
容器运行时中的Kubernetes相关容器和镜像。
sudo kubeadm reset --force --cri-socket unix:///var/run/cri-dockerd.sock
rm -rf ~/.kube
正确输出如下:
然后再重新添加到node节点就可以了。
kubeadm join 192.168.56.7:6443 --token iuirah.g5xgliaj0xoexot3 \
--discovery-token-ca-cert-hash sha256:febac1a7e34272f5aa4a5aefa5aeb6ee7628a3b7f0283a41d919cd2cae945800 \
--cri-socket unix:///var/run/cri-dockerd.sock
4、牵引出来的docker代理问题
docker没办法拉取,例如:docker pull nginx一直报错response from daemon: Get "https://index.docker.io/v1/search?q=nginx&n=25": proxyconnect tcp: dial tcp 192.168.49.2:8080: connect: connection refused
这个是因为之前用了minikube,docker引用了这个代理,后续想要用自己的/etc/docker/的json镜像源结果就报错了。
deepseek解释:
残留代理配置:用户之前可能为Docker配置了代理(如HTTP_PROXY=http://192.168.49.2:8080),而该代理服务器(如minikube虚拟机内的代理、本地临时代理工具)已停止运行或IP/端口变更(192.168.49.2通常是minikube的默认IP,若minikube已卸载或停止,代理服务随之关闭)。
解决方法:清除Docker的代理配置
步骤1:清除系统环境变量中的代理
Docker可能继承系统级代理变量(如HTTP_PROXY),需临时清除并永久删除配置文件中的残留:
临时清除当前终端的代理变量(立即生效):
unset HTTP_PROXY
unset HTTPS_PROXY
unset NO_PROXY
unset http_proxy
unset https_proxy
unset no_proxy
2.永久删除配置文件中的代理变量(避免重启后恢复):
如果~/.bashrc有相关的配置,那么删除配置文件中的代理变量,在文件中查找包含HTTP_PROXY HTTPS_PROXY的行(如export HTTP_PROXY=http://192.168.49.2:8080),删除或注释(在行首加#),保存退出,source ~/.bashrc # 使修改生效。
步骤2:清除Docker服务的代理配置(若通过systemd配置)
若通过systemd服务文件配置过代理(如/etc/systemd/system/docker.service.d/proxy.conf),需删除该文件:
删除代理配置文件
sudo rm -f /etc/systemd/system/docker.service.d/proxy.conf # 彻底删除残留代理配置
重启Docker服务:
sudo systemctl daemon-reload # 重新加载systemd配置
sudo systemctl restart docker # 重启Docker,使代理清除生效
3、下载Kubernetes v1.30.10组件镜像的方法(基于阿里云镜像源与kubeadm命令,无需额外工具)
一、通过阿里云镜像源手动拉取(推荐国内环境)
阿里云提供了Kubernetes官方镜像的同步仓库,可直接通过docker pull拉取v1.30.10版本组件镜像,无需访问国外仓库。
1. 核心镜像列表(v1.30.10)
Kubernetes集群需以下核心镜像(以amd64架构为例),镜像名称格式为:
registry.aliyuncs.com/google_containers/<组件名称>:v1.30.10
2. 手动拉取命令(逐条执行)
# 拉取控制平面组件
docker pull registry.aliyuncs.com/google_containers/kube-apiserver:v1.30.10
docker pull registry.aliyuncs.com/google_containers/kube-controller-manager:v1.30.10
docker pull registry.aliyuncs.com/google_containers/kube-scheduler:v1.30.10
# 拉取节点组件与基础镜像
docker pull registry.aliyuncs.com/google_containers/kube-proxy:v1.30.10
docker pull registry.aliyuncs.com/google_containers/pause:3.9
docker pull registry.aliyuncs.com/google_containers/etcd:3.5.12-0 # 仅集群使用内置etcd时需拉取
3. 验证镜像拉取结果
docker images | grep v1.30.10 # 应显示上述组件镜像及对应版本
二、通过kubeadm命令自动拉取(推荐集群初始化场景)
kubeadm提供了一键拉取集群所需镜像的命令,结合阿里云镜像源配置,可自动拉取v1.30.10所有组件镜像。
1. 配置kubeadm使用阿里云镜像源
创建kubeadm配置文件(kubeadm-config.yaml),指定阿里云镜像仓库:
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
kubernetesVersion: v1.30.10
imageRepository: registry.aliyuncs.com/google_containers # 阿里云镜像仓库地址
2. 执行kubeadm拉取命令
作用:根据配置文件中的imageRepository和kubernetesVersion,自动拉取v1.30.10所需的所有组件镜像(包含控制平面、节点组件、etcd、pause等)。
kubeadm config images pull --config=kubeadm-config.yaml
3. 验证拉取结果
docker images | grep registry.aliyuncs.com/google_containers # 显示所有拉取的镜像
三、关键说明
镜像版本对应关系:
Kubernetes v1.30.x默认使用pause:3.9和etcd:3.5.12-0,无需手动指定,kubeadm会自动匹配对应版本。
架构适配:
上述镜像为amd64架构,若为arm64等其他架构,需在镜像名称后添加架构标签(如-arm64),例如:
registry.aliyuncs.com/google_containers/kube-apiserver:v1.30.10-arm64
离线环境使用:拉取完成后,可通过docker save将镜像保存为tar包,传输到离线节点后用docker load加载:
docker save -o k8s-v1.30.10-images.tar \
registry.aliyuncs.com/google_containers/kube-apiserver:v1.30.10 \
registry.aliyuncs.com/google_containers/kube-controller-manager:v1.30.10 \
registry.aliyuncs.com/google_containers/kube-scheduler:v1.30.10 \
registry.aliyuncs.com/google_containers/kube-proxy:v1.30.10 \
registry.aliyuncs.com/google_containers/pause:3.9 \
registry.aliyuncs.com/google_containers/etcd:3.5.12-0
5、K8s 初始化之后,就可以在其他 2 个工作节点上执行 “kubeadm join” 命令,因为我们使用了 cri-dockerd ,需要在命令加上 “–cri-socket=unix:///var/run/cri-dockerd.sock” 参数。
命令中 token 有效期为 24 小时,当 token 过期之后,执行 “kubeadm join” 命令就会报错。这时可以直接在 Master 节点上使用以下命令生成新的 token,然后再使用 “kubeadm join” 命令加入节点。
此时,我们的集群就部署成功了。你可以使用 “kubectl get node” 命令来查看集群节点状态。
# 在两个工作节点上执行
kubeadm join 192.168.9.86:6443 --token xxxxxx \
--discovery-token-ca-cert-hash sha256:xxxxxx \
--cri-socket=unix:///var/run/cri-dockerd.sock
泽鹏的:
kubeadm join 192.168.56.7:6443 --token iuirah.g5xgliaj0xoexot3 \
--discovery-token-ca-cert-hash sha256:febac1a7e34272f5aa4a5aefa5aeb6ee7628a3b7f0283a41d919cd2cae945800 \
--cri-socket unix:///var/run/cri-dockerd.sock
步骤1:在Master节点生成新的token和join命令
在集群的Master节点执行以下命令,生成新的token及完整的kubeadm join命令(包含CA证书哈希,有效期24小时)
查询当前的token清单
kubeadm token list
kubeadm token create --print-join-command
输出示例(直接复制此命令到Node节点执行)
kubeadm join 192.168.56.7:6443 --token abcdef.0123456789abcdef --discovery-token-ca-cert-hash sha256:xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx
网络要求:Node节点需能访问Master节点的6443端口(API Server端口),确保无防火墙拦截。
6、如果有多台master集群点,需要如何配置:
Kubernetes多Master节点(高可用)的核心是共享同一套集群CA证书和etcd数据,通过负载均衡器(如HAProxy、Nginx)暴露API Server。流程如下:
1. 初始化第一个Master节点(执行一次kubeadm init)
kubeadm init \
--apiserver-advertise-address=<第一个Master节点IP> \ # 仅需在此处指定当前节点IP
--control-plane-endpoint=<负载均衡器IP:端口> \ # 高可用必填,指向负载均衡器
--upload-certs # 自动上传CA证书,供后续Master节点加入时使用
作用:生成集群CA证书、API Server配置、etcd数据,并初始化控制平面组件(kube-apiserver、kube-controller-manager等)。
2. 加入其他Master节点(执行kubeadm join)
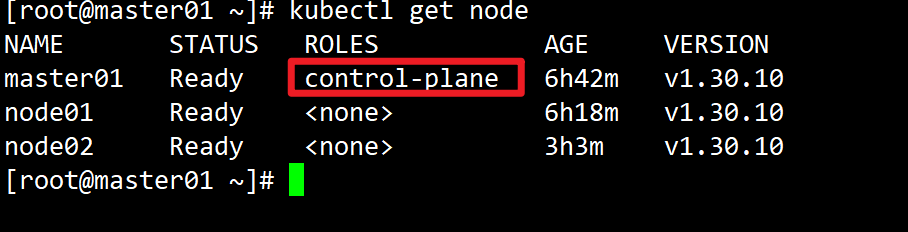
使用init命令输出的控制平面加入命令(包含证书密钥和负载均衡器地址),在其他Master节点执行:区别普通node是添加join的时候增加这个--control-plane
通过role的kubectl get node 可以看到哪个是主节点
kubeadm join <负载均衡器IP:端口> \
--token <初始化时生成的token> \
--discovery-token-ca-cert-hash <CA证书哈希> \
--control-plane \ # 标识为控制平面节点
--certificate-key <初始化时上传的证书密钥> # 通过--upload-certs生成
作用:以控制平面节点身份加入集群,共享CA证书和etcd数据,无需再次执行init。
提醒:为何不能执行多条kubeadm init?
kubeadm init会创建新集群:每次执行init会生成独立的CA证书和etcd集群,导致多个独立集群,而非同一集群的多Master节点。
资源冲突:重复init会导致端口占用(如6443、2379)、数据目录冲突(如/var/lib/etcd),引发启动失败。